Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
Perplexity’s strategy behind its new Pages feature created a deep rift with publishers, but the reaction seems blown out of proportion. It’s much more interesting as a case study for user-directed AI content (UDC instead of UGC).
Perplexity Pages allows users to “create beautifully designed, comprehensive articles on any topic.” You can turn a thread, a prompt sequence, into a page about a topic.
As a regular Growth Memo reader, you quickly grasp that this is a growth strategy where, ideally, users create AI content that ranks in organic search and brings visitors to perplexity.ai that converts into paying subscribers.
The growth strategy fits into what CEO Srinivas explains as “an aggregator of information.” It holds power by providing a superior user experience, which allows it to channel demand and commoditize supply.
Drop In The Bucket
When we look at actual data, we can see that the media reaction is overblown. Not in the critique but in impact. It’s fair to ask Perplexity to adjust attribution, follow web standards like robots.txt, and use official IPs like search engines do as well.
According to developer Ryan Knight, Perplexity crawls the web with a headless browser that masks its IP string.
CEO Srinivas said Perplexity obeys robots.txt, and the masked IP came from a third-party service. But he also mentioned that “the emergence of AI requires a new kind of working relationship between content creators, or publishers, and sites like his.”
But in terms of benefit for Perplexity, Pages is a drop in the bucket.
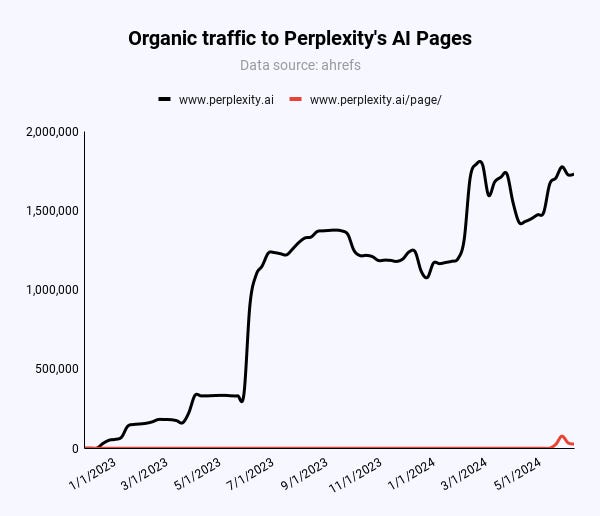 Image Credit: Kevin Indig
Image Credit: Kevin Indig91% of organic traffic to perplexity.ai comes from branded terms like “perplexity.”
Only 47,000 out of 217,000 (21.6%) monthly visitors to Pages come from organic, non-branded keywords globally.
In the US, it’s 55% (20,000/36,000). However, compared to x monthly visits from branded terms, Pages doesn’t make a dent in Perplexity’s organic traffic.
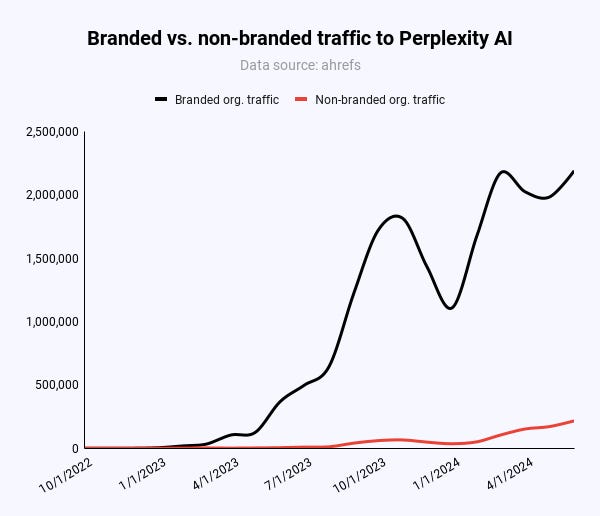 Image Credit: Kevin Indig
Image Credit: Kevin IndigIn reality, most traffic to Perplexity comes through its brand and word of mouth. The recent media coverage might have helped Perplexity more than it harmed. The site has hit new all-time traffic highs every day since January 2024, according to Similarweb.
Perplexity’s whole domain has only 950 pages, of which Pages make up almost 600. Compared to other sites – like Wikipedia’s 6.8 million articles on the English version alone – that’s just not a lot. Stronger scale effects will emerge as Pages get more traction. Right now, Pages is a nascent beta feature.
Taking a closer look at its performance, the most searched-for keyword Pages rank in the top 3 for is “was candy montgomery guilty” (600 MSV). The most difficult keyword it ranks in position one for is “when was the first bitcoin purchase” (KD: 76, MSV: 30). In other words, Pages still has a long way to go.
An n=1 (!) text similarity comparison with GoTranscript between Perplexity’s page for “bitcoin pizza day” and its four linked sources shows little evidence of plagiarism:
- nationaltoday.com/bitcoin-pizza-day/ (15% similarity).
- www.uledger.io/post/bitcoin-pizza-day-history (27% similarity).
- coinedition.com/bitcoin-pizza-day-a-700-million-reminder-of-cryptocurrencys-rise/ (15%).
- www.investopedia.com/news/bitcoin-pizza-day-celebrating-20-million-pizza-order/ (9%).
 Text comparison between Perplexity’s and NationalToday’s article about Bitcoin Pizza Day (Image Credit: Kevin Indig)
Text comparison between Perplexity’s and NationalToday’s article about Bitcoin Pizza Day (Image Credit: Kevin Indig)The “missing” attribution issue seems to have been fixed, as the example below shows.
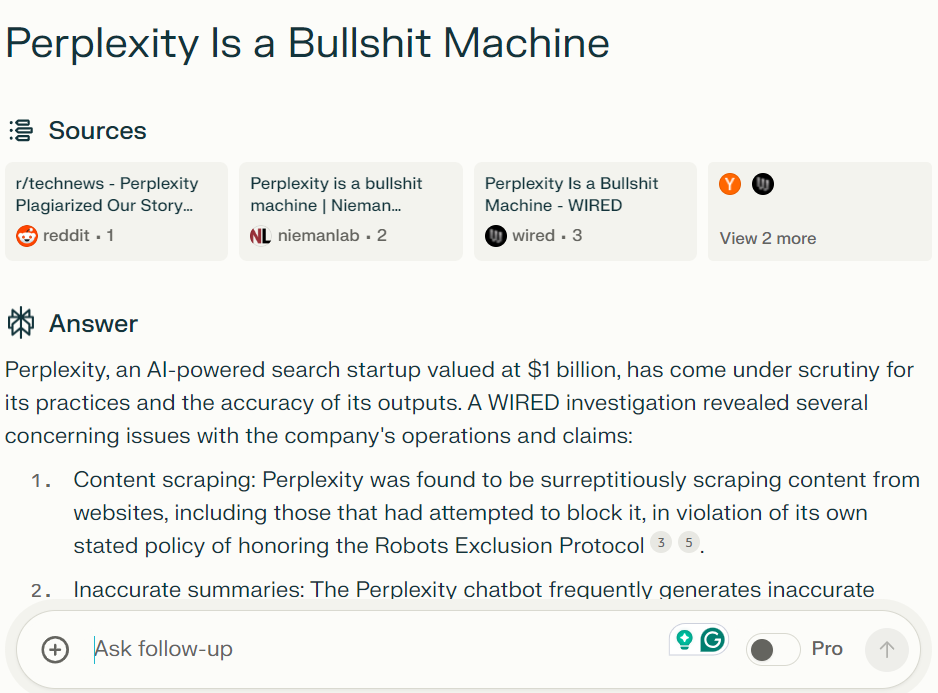 Perplexity highlights sources for answers at the top (Image Credit: Kevin Indig)
Perplexity highlights sources for answers at the top (Image Credit: Kevin Indig)The results showed the chatbot at times closely paraphrasing WIRED stories, and at times summarizing stories inaccurately and with minimal attribution.
I wasn’t able to confirm or deny cases of hallucination, but I expect better models to get to a point at which they can summarize existing content flawlessly. The reality is, we’re not there yet. Google’s AI Overviews have also been shown to include wrong facts or make things up.
Google seems to have been able to improve the problem quickly, which is why I expect the degree of hallucination to drop.
One underlying issue of the plagiarism critique is that a search for the exact title of an article returns that article.
Of course, Perplexity should return a summary of an article when users prompt it. What else should Perplexity show? The same argument came up in the lawsuit between OpenAI and the NY Times.
Triggered
Besides the crawling issues Perplexity needs to fix, the media’s reaction seems to be triggered by Perplexity’s positioning.
One sentence in Perplexity’s announcement of Pages gets to the heart of the underlying issue:
“With Pages, you don’t have to be an expert writer to create high quality content.”
The page also mentions:
”Crafting content that resonates can be difficult. Pages is built for clarity, breaking down complex subjects into digestible pieces and serving everyone from educators to executives.”
All examples of Pages listed in the announcement are about “how to” or “what is” topics:
- “Beginner’s guide to drumming”
- “How to use an AeroPress”
- “Writing Kubernetes CronJobs”
- “Steve Jobs: Visionary CEO”
- Etc.
That’s exactly the challenge AI poses to writers: AI can increasingly cover clearly defined content formats like guides or tutorials. I can see how this is triggering to journalists.
User-Directed Content
Note how Perplexity doesn’t create all the content for Pages but takes direction from humans through prompts (UDC).
Instead of writing a whole article, humans put the puzzle pieces together and their author bio stamp on a Page.
I expect the same to happen with other content types like reviews and platforms like Google, Tripadvisor, Yelp, G2 & Co. to provide corresponding tools to make content creation easier. The biggest challenge will be to keep quality high and reduce useless information to a minimum.
The big question is whether a build like Pages can compete with a purely human-written site like Wikipedia, which currently has 116,000 active contributors.
The bigger “Growth play” behind pages (IMHO) is how Perplexity creates AI (video) podcasts out of summarized articles that outrank original results.
“Perplexity then sent this knockoff story to its subscribers via a mobile push notification. It created an AI-generated podcast using the same (Forbes) reporting — without any credit to Forbes, and that became a YouTube video that outranks all Forbes content on this topic within Google search.”
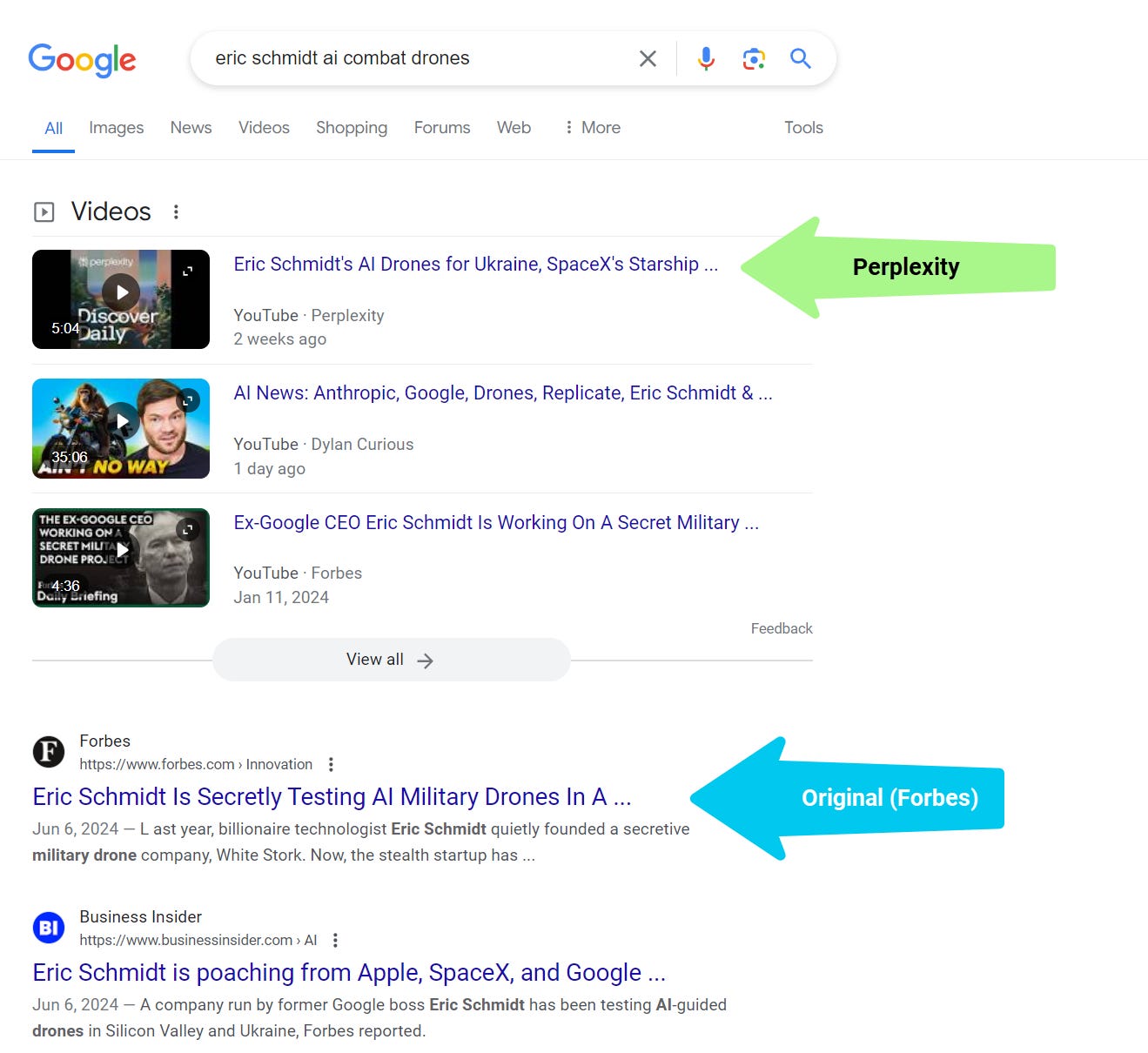 Perplexity outranks publishers with video podcasts summarizing articles (Image Credit: Kevin Indig)
Perplexity outranks publishers with video podcasts summarizing articles (Image Credit: Kevin Indig)Google will have to figure out how to prevent LLMs from repurposing the content of publishers.
What remains after examining the facts is the realization of how difficult it is to balance giving an AI answer while sending traffic to sources. Why should users click when most of their questions are answered?
On the other side of the coin, publishers themselves can provide summaries of their articles. Therefore, the key challenge for Perplexity – and anyone else who wants to create large-scale AI content for Search – is adding unique value on top of AI summaries.
The path to unique value from AI summaries and other AI content is personalization.
A system that can recognize your preferences of level of understanding for a topic can make AI summaries more useful to you. Perplexity is a wrapper around different LLMs, but if it collects significant information about users and personalizes output, it can add value beyond fast answers.
Device operating system makers like Alphabet and Apple have the biggest advantage when it comes to user data since they sit on top of the food chain.
A strong example is Apple Intelligence, which could likely answer questions currently provided by guides and tutorials on Google or Perplexity.
Apple Intelligence (abbreviated “AI” – nice one, Apple!) has full context through location (Apple Maps), third-party app usage, Siri prompts, email (Apple Mail), and other sources, which creates a nice base to personalize results on. The web is just one body of knowledge, with a much sexier one waiting on our Dropbox, Gmail inbox, and iPhone photos.
Today, personalized answers are a vision and a demo.
But at some point in the future, personalization will create better answers than any generic LLM summary and surely more than any human-written guide.
The value of defined and generic knowledge is on a collision course with LLM bombers. At the same time, the value of personalized knowledge, human experience, and trustworthy expert expertise is skyrocketing.
AI startup Perplexity wants to upend search business. News outlet Forbes says it’s ripping them off; Integrator vs Aggregator Growth
Perplexity AI Is Lying about Their User Agent
Perplexity CEO Aravind Srinivas responds to plagiarism and infringement accusations
Why Perplexity’s Cynical Theft Represents Everything That Could Go Wrong With AI
Featured Image: Paulo Bobita/Search Engine Journal