Questions about the methodology used by the Pew Research Center suggest that its conclusions about Google’s AI summaries may be flawed. Facts about how AI summaries are created, the sample size, and statistical reliability challenge the validity of the results.
Google’s Official Statement
A spokesperson for Google reached out with an official statement and a discussion about why the Pew research findings do not reflect actual user interaction patterns related to AI summaries and standard search.
The main points of Google’s rebuttal are:
- Users are increasingly seeking out AI features
- They’re asking more questions
- AI usage trends are increasing visibility for content creators.
- The Pew research used flawed methodology.
Google shared:
“People are gravitating to AI-powered experiences, and AI features in Search enable people to ask even more questions, creating new opportunities for people to connect with websites.
This study uses a flawed methodology and skewed queryset that is not representative of Search traffic. We consistently direct billions of clicks to websites daily and have not observed significant drops in aggregate web traffic as is being suggested.”
Sample Size Is Too Low
I discussed the Pew Research with Duane Forrester (formerly of Bing, LinkedIn profile) and he suggested that the sampling size of the research was too low to be meaningful (900+ adults and 66,000 search queries). Duane shared the following opinion:
“Out of almost 500 billion queries per month on Google and they’re extracting insights based on 0.0000134% sample size (66,000+ queries), that’s a very small sample.
Not suggesting that 66,000 of something is inconsequential, but taken in the context of the volume of queries happening on any given month, day, hour or minute, it’s very technically not a rounding error and were it my study, I’d have to call out how exceedingly low the sample size is and that it may not realistically represent the real world.”
How Reliable Are Pew Center Statistics?
The Methodology page for the statistics used list how reliable the statistics are for the following age groups:
- Ages 18-29 were ranked at plus/minus 13.7 percentage points. That ranks as a low level of reliability.
- Ages 30–49 were ranked at plus/minus 7.9 percentage points. That ranks in the moderate, somewhat reliable, but still a fairly wide range.
- Ages 50–64 were ranked at plus/minus 8.9 percentage points. That ranks as a moderate to low level of reliability.
- Age 65+ were ranked at at plus/minus 10.2 percentage points, which is firmly in the low range of reliability.
The above reliability scores are from Pew Research’s Methodology page. Overall, all of these results have a high margin of error, making them statistically unreliable. At best, they should be seen as rough estimates, although as Duane says, the sample size is so low that it’s hard to justify it as reflecting real-world results.
Pew Research Results Compare Results In Different Months
After thinking about it overnight and reviewing the methodology, an aspect of the Pew Research methodology that stood out is that they compared the actual search queries from users during the month of March with the same queries the researchers conducted in one week in April.
That’s problematic because Google’s AI summaries change from month to month. For example, the kinds of queries that trigger an AI Overview changes, with AIOs becoming more prominent for certain niches and less so for other topics. Additionally user trends may impact what gets searched on which itself could trigger a temporary freshness update to the search algorithms that prioritize videos and news.
The takeaway is that comparing search results from different months is problematic for both standard search and AI summaries.
Pew Research Ignores That AI Search Results Are Dynamic
With respect to AI overviews and summaries, these are even more dynamic, subject to change not just for every user but to the same user.
Searching for a query in AI Overviews then repeating the query in an entirely different browser will result in a different AI summary and completely different set of links.
The point is that the Pew Research Center’s methodology where they compare user queries with scraped queries a month later are flawed because the two sets of queries and results cannot be compared, they are each inherently different because of time, updates, and the dynamic nature of AI summaries.
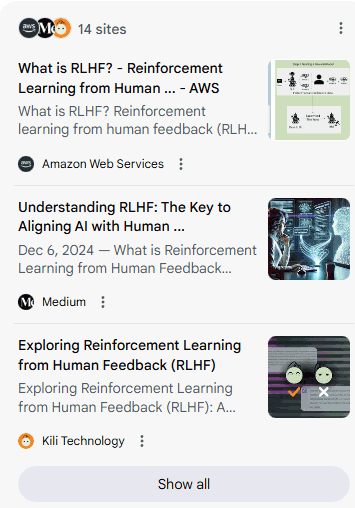
The following screenshots are the links shown for the query, What is the RLHF training in OpenAI?
Google AIO Via Vivaldi Browser
Google AIO Via Chrome Canary Browser
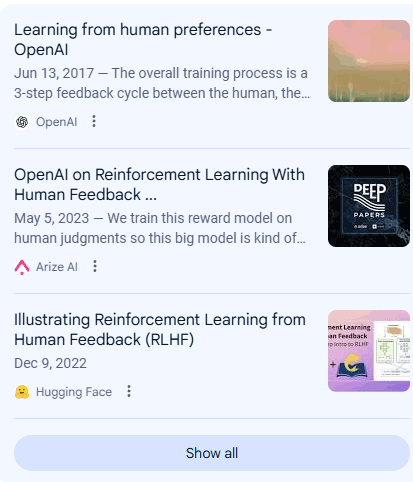
Not only are the links on the right hand side different, AI summary content and the links embedded within that content are also different.
Could This Be Why Publishers See Inconsistent Traffic?
Publishers and SEOs are used to static ranking positions in search results for a given search query. But Google’s AI Overviews and AI Mode show dynamic search results. The content in the search results and the links that are shown are dynamic, showing a wide range of sites in the top three positions for the exact same queries. SEOs and publishers have asked Google to show a broader range of websites and that, apparently, is what Google’s AI features are doing. Is this a case of be careful of what you wish for?
Featured Image by Shutterstock/Stokkete